9月
10
精选文章
该后台使用 vite + ts + pnpm + vue3 + element-plus + tailwindcss 等技术栈构成。没有添加任意可视化图标等插件。以最小功能,最基础功能展现。用户可以额外添加可使用的插件逻辑。
该后台后端使用 php8.2 + laravel 10 + mysql
该后台后端 go 语言版本开发中。将使用 gframe2.5.2
源码: https://github.com/vini123/simpleAdmin
在线体验: https://www.zeipan.com/admin
权限以及密码一键复位: https://v3test.yuepaibao.com/admin/api/reset
测试账号以及密码: zhoulin@xiangrong.pro、 111111 (如果发现登录不了,可一键复位谢谢)
6月
05
精选文章
5月
30
安卓插件开发教程 https://nativesupport.dcloud.net.cn/NativePlugin/course/android.html
插件包格式 https://nativesupport.dcloud.net.cn/NativePlugin/course/package.html
参考
https://juejin.cn/post/7439935260241018930
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDlpVM5OyPFQmOjsBxaLRaLWZ/6YuxJrrAGpwvKJlDGBUpNoTjS3TkE4Jw9nvG8lZHPx4ywNV5KTljHwqlGrIv3j5ad4lXqgJEyGrleDHTSUgdLNN00er7PpKmJqgCyPT25YsaTuwMzNLhVCd8XO/ptxJx3KkIX2IgFi5pl4lSBe/EYW4yeyJTM7YI0wIDc3a9/O1Ns44U8HWg9fS9aq/FxkXCpTTCBu2b1KQvdZMyRg0YkfR7qDZtasIHu5rYzkLszjv1a97WfePzbPdK6THb6EIGUc83C749SOYIOX5abdl9vIkDiBcfOctr2hjJZUlCGh5BEBPs4dpEA7Jm0gfcEcq2XlEqqybwiW6PhkLkwfY6Ybpq6uSxDatfRDgT6uisoYsLokVhBicu9L1PYlzrHAs6MMnYi9v62eaGz5eghitR8mbzr2gzdIX/dCPsgTXiQ3Mq2eRnuCfBuK/Z1WCkeY2Fpx30/oEZRnsYSWy686oAWRdd8xqVdRrvBKIYRYj8= zhoulin@xiangrong.pro
5月
08
https://docs.unity3d.com/cn/2021.3/Manual/webgl-interactingwithbrowserscripting.html
unity 调用 js
请使用 .jslib 扩展名将包含 JavaScript 代码的文件放置在 Assets 文件夹中的“Plugins”子文件夹下。格式如下。
mergeInto(LibraryManager.library, {
Hello: function () {
window.alert("Hello, world!");
},
HelloString: function (str) {
window.alert(UTF8ToString(str));
}
});
5月
08
如果不需要泛域名证书,可以不用安装对应域名运营商的 cli 工具
nginx 镜像
仅安装 certbot 的 Dockerfile
ARG NGINX_IMAGE
FROM ${NGINX_IMAGE}
# 安装 certbot https://certbot.eff.org/instructions?ws=nginx&os=snap
# 也可以在 nginx 之外使用 certbot 镜像 https://hub.docker.com/r/certbot/certbot
RUN apt-get update && \
apt-get install -y python3-venv && \
python3 -m venv /opt/certbot && \
/opt/certbot/bin/pip install certbot certbot-nginx && \
ln -s /opt/certbot/bin/certbot /usr/local/bin/certbot && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
安装 certbot 和 aliyun cli 的Dockerfile
ARG NGINX_IMAGE
FROM ${NGINX_IMAGE}
# 安装 certbot https://certbot.eff.org/instructions?ws=nginx&os=snap
# 也可以在 nginx 之外使用 certbot 镜像 https://hub.docker.com/r/certbot/certbot
RUN apt-get update && \
apt-get install -y wget python3-venv && \
python3 -m venv /opt/certbot && \
/opt/certbot/bin/pip install certbot certbot-nginx && \
ln -s /opt/certbot/bin/certbot /usr/local/bin/certbot && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
# 安装阿里云 cli https://help.aliyun.com/zh/cli/install-cli-on-linux?spm=a2c4g.11174283.0.0.5df9478dHNZ4T9
# https://help.aliyun.com/zh/cli/run-alibaba-cloud-cli-in-a-docker-container
RUN mkdir -p /soft && \
cd /soft && \
wget -q https://aliyuncli.alicdn.com/aliyun-cli-linux-latest-amd64.tgz && \
tar -xzvf aliyun-cli-linux-latest-amd64.tgz && \
cp aliyun /usr/local/bin/ && \
rm -rf /soft/aliyun-cli-linux-latest-amd64.tgz
# 验证阿里云 CLI 是否安装成功
RUN aliyun version
构建镜像,当前 nginx 最新版本是 1.28.0
docker build --build-arg NGINX_IMAGE=nginx:1.28.0 -t nginx-certbot .
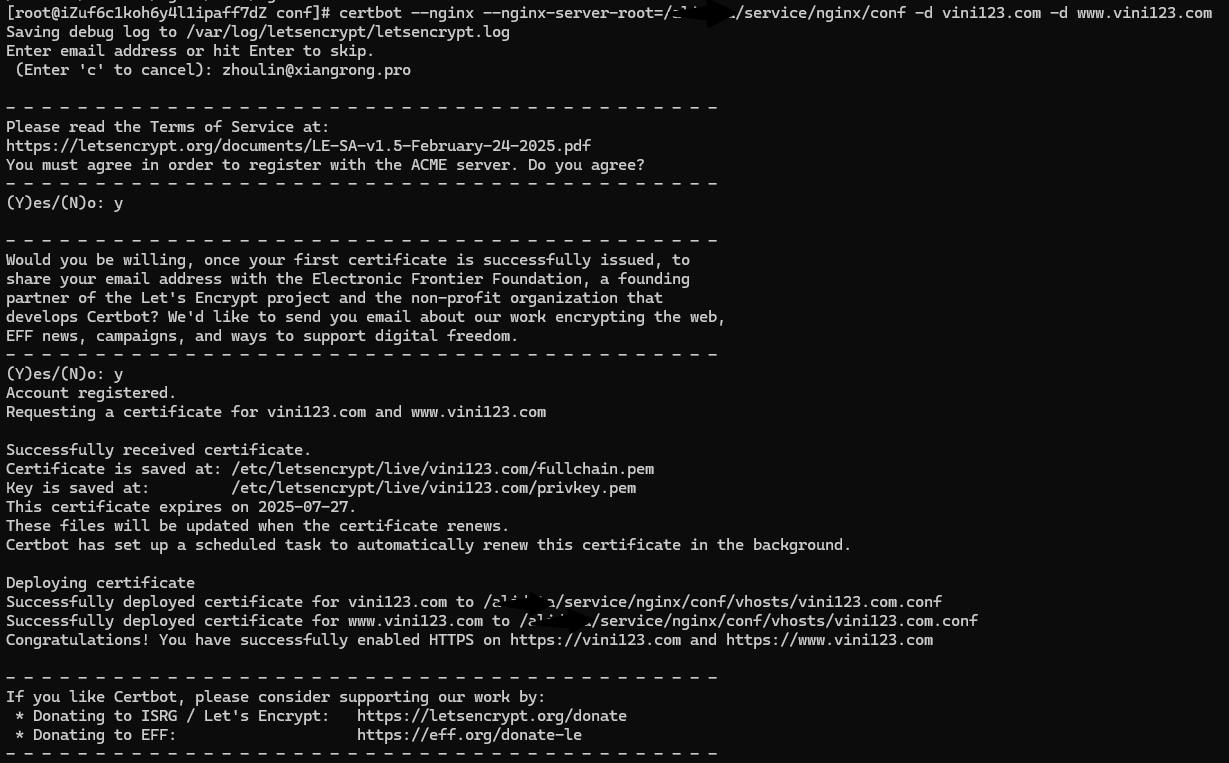
手动生成证书
假设服务器上已经使用了该 nginx 镜像。并且配置文件目录是 /etc/nginx/。假如某个 .conf 文件使用了 vini123.com 的证书。就可以通过一下命令生成。
# 找到容器的名字或 id 前三位
docker ps
# 生成证书
docker exec -i nginx1.28.0 certbot --nginx --nginx-server-root=/etc/nginx -d vini123.com -d www.vini123.com
docker exec 常用 option 说明。
常用选项
-d:在后台运行命令。
-i:保持 STDIN 打开,即使没有附加。
-t:分配一个伪终端。
-u:指定在容器内执行命令的用户。
--workdir:指定容器内的工作目录。
注意
因为 certbot 安装在了 nginx 容器内。如果执行 docker-compose down 再执行 docker-compose up -d 就会丢失证书。所以在构建 nginx 容器的时候,一定要配置好证书的 volume。就是 certbot 生成的证书位置和本地宿主机的一个映射。
4月
28
https://certbot.eff.org/instructions?ws=nginx&os=snap&tab=standard
安装
安装 snapd
https://snapcraft.io/docs/installing-snap-on-centos
https://snapcraft.io/docs/installing-snapd
yum install snapd
systemctl enable --now snapd.socket
ln -s /var/lib/snapd/snap /snap
看看 snapd 状态。 snap changes
安装 certbot
snap install --classic certbot
建立软链
ln -s /snap/bin/certbot /usr/bin/certbot
生成证书
必须服务器先安装好 nginx。
生成单个域名证书
生第一个域名证书的时候,会让你输入 email,然后同意协议(y 回车即可)。生成一次后,后边的域名就直接生成了。
可以在任意位置执行该命令。
生成成功的同时,nginx 也一起重启了。也就是生成后,证书就 ok了。
证书续期
生成的证书有效期是 3 个月的。3个月后,需要新的证书。这里用续期处理。
certbot renew --dry-run
可以通过定时任务来续订。
生泛域名证书
参考
https://www.cnblogs.com/michaelshen/p/18538178
4月
27
coturn
https://github.com/coturn/coturn/
安装
安装依赖
yum install -y make gcc cc gcc-c++ wget openssl-devel libevent libevent-devel
下载和编译
cd /usr/local/src
wget https://codeload.github.com/coturn/coturn/tar.gz/refs/tags/4.6.2
tar -xzvf coturn-4.6.2.tar.gz
cd coturn-4.6.2
./configure
make
make install
安装结束时的最后几行日志。
install -p examples/etc/turnserver.conf /usr/local/etc/turnserver.conf.default
cp -rpf examples/etc /usr/local/share/examples/turnserver
cp -rpf examples/scripts /usr/local/share/examples/turnserver
rm -rf /usr/local/share/examples/turnserver/scripts/rfc5769.sh
cp -rpf include/turn/client /usr/local/include/turn
install -p include/turn/ns_turn_defs.h /usr/local/include/turn
cat /usr/local/share/doc/turnserver/postinstall.txt
检查安装
which turnserver
输出:/usr/local/bin/turnserver
配置 turn
cd /usr/local/etc
cp turnserver.conf.default turnserver.conf
配置以下信息。
listening-port=3478 # 监听的端口
listening-ip=0.0.0.0 # 监听的内网IP
external-ip=x.x.x.x # 监听的外网IP
user=user:123456 # 设置账号密码
realm=xxx.com # realm 名称,通常是一个域名
no-tls
no-dtls
verbose
log-file=/var/log/turn.log # 配置日志位置
配置自启动
添加
vim /usr/lib/systemd/system/turnserver.service
# 配置以下内容
[Unit]
Description=turnserver for p2p
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/bin/turnserver -o -c /usr/local/etc/turnserver.conf
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target
# :wq 保存
启用
- systemctl daemon-reload 重置服务列表
- systemctl enable turnserver.service 开启开机自启
- systemctl start turnserver.service 启动服务
- systemctl restart turnserver.service 重启服务
- systemctl status turnserver.service 查看状态
- systemctl disable turnserver.service 关闭开机自启。()不关闭,就不执行这个)
查看进程
ps -ef|grep turnserver
# 只显示主进程
pgrep -a turnserver
查看监听端口。
netstat -tulnp | grep turnserver
查看 3478 端口。
lsof -i :3478
测试检查
turnutils_uclient -v -t -y -u user -w password ip
替换对应的 user, password, ip 为配置的值。
或网页测试
https://webrtc.github.io/samples/src/content/peerconnection/trickle-ice/
参考
https://sanyers.github.io/blog/web/webrtc/turn%E6%9C%8D%E5%8A%A1%E5%99%A8%E9%83%A8%E7%BD%B2.html#_6%E3%80%81%E5%90%AF%E5%8A%A8%E6%9C%8D%E5%8A%A1
https://coturn.net/turnserver/
https://github.com/coturn/coturn/wiki/Downloads
4月
22
go-stress-testing
https://github.com/link1st/go-stress-testing
如果没有环境可以去下作者编译好的: https://github.com/link1st/go-stress-testing/releases
go clone https://github.com/link1st/go-stress-testing.git
cd go-stress-testing
go build
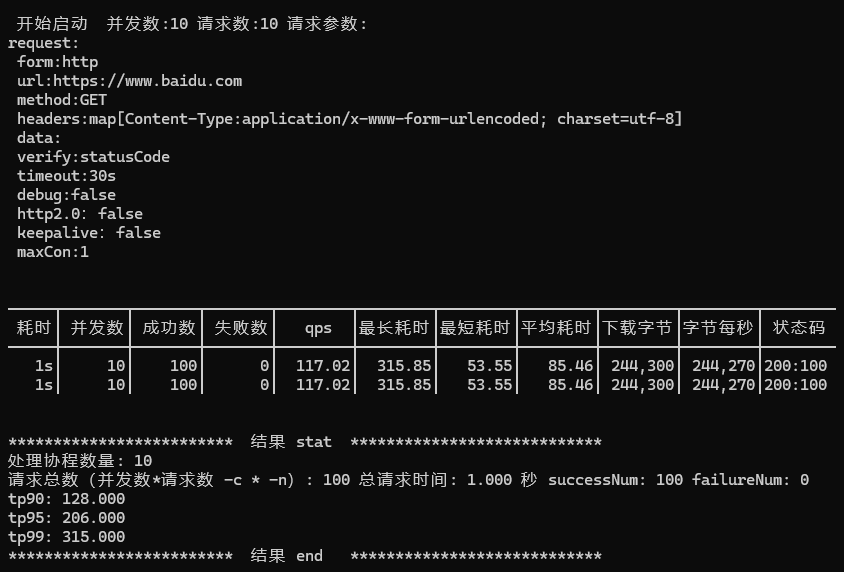
执行测试:
.\go-stress-testing.exe -c 10 -n 10 -u https://www.baidu.com
返回结果:
参考
https://cloud.tencent.com/developer/article/1509809
go-wrk
https://github.com/adjust/go-wrk
操作
自身系统有 go 环境。
git clone https://github.com/adjust/go-wrk.git
cd go-wrk
go mod init go-wrk
go build
执行测试。
./go-wrk [flags] url
例子:
./go-wrk -c=400 -t=8 -n=100000 http://localhost:8080/index.html
flags
-H="User-Agent: go-wrk 0.1 bechmark\nContent-Type: text/html;": the http headers sent separated by '\n'
-c=100: the max numbers of connections used
-k=true: if keep-alives are disabled
-i=false: if TLS security checks are disabled
-m="GET": the http request method
-n=1000: the total number of calls processed
-t=1: the numbers of threads used
-b="" the http request body
-s="" if specified, it counts how often the searched string s is contained in the responses
3月
28
长期维护,国内镜像。请访问 https://cloud.tencent.com/developer/article/2485043
centos
# 打开或新建 daemon.json
vim /etc/docker/daemon.json
# 加入一下配置
{
"registry-mirrors": [
"https://docker.1ms.run",
"https://docker.xuanyuan.me"
]
}
# 重启
sudo systemctl daemon-reload
sudo systemctl restart docker
3月
26
docker 备份数据库
- 创建
/user/local/src/backup/mysql-backup.sh 文件。
#!/bin/bash
CONTAINER_NAME="mysql8.2" # MySQL容器名称
MYSQL_PWD="xxxxxx" # 数据库密码
MYSQL_DATABASE="xxxxxx" # 数据库名称
BACKUP_DIR="/user/local/src/backup/mysql" # 备份存储目录
LOG_DIR="/user/local/src/backup/logs" # 备份存储目录
DATE=$(date +"%Y%m%d")
# 确保备份目录存在
mkdir -p "$BACKUP_DIR"
mkdir -p "$LOG_DIR"
# 每周日进行全量备份
if [[ $(date +%u) -eq 7 ]]; then
echo "开始备份..."
BACKUP_FILE="$BACKUP_DIR/mysql_full_$DATE.sql"
docker exec $CONTAINER_NAME sh -c "mysqldump -uroot -p'$MYSQL_PWD' $MYSQL_DATABASE" >"$BACKUP_FILE"
gzip "$BACKUP_FILE"
echo "备份完成并压缩,存储路径:$BACKUP_FILE.gz"
else
echo "今天不是周天,不备份"
fi
如果备份所有数据库。mysqldump --all-databases -uroot -p'$MYSQL_PWD'
- 设置权限
chmod +x /user/local/src/backup/mysql-backup.sh
- 添加定时任务\
crontab -e
#每天凌晨 2 点启动定时任务
0 2 * * * bash /user/local/src/backup/mysql-backup.sh >> /user/local/src/backup/logs/backup_$(date +\%Y\%m\%d).log 2>&1